Data Conversion, Maintenance and Scale
Notes on the Breakout Group
Kevin Curtin, Janine Gottlieb
Participants
Marion Storey (City of Philadelphia, Streets)
Robert Cheetham (City of Philadelphia, MOIS)
Jim Querry (City of Philadelphia, MOIS)
Bjorke Brun (ScanRail Consulting)
Lee Samson (Wisconsin DOT)
Jay Sandhu (ESRI)
Peter Morey (Minnesota DOT)
Kevin Curtin (UCSB)
Todd Crane (GDT)
Frank Winters (NY DOT)
3 Main Points were generated by this breakout group:
1. Diagram
Initial Data Maintenance Object Model
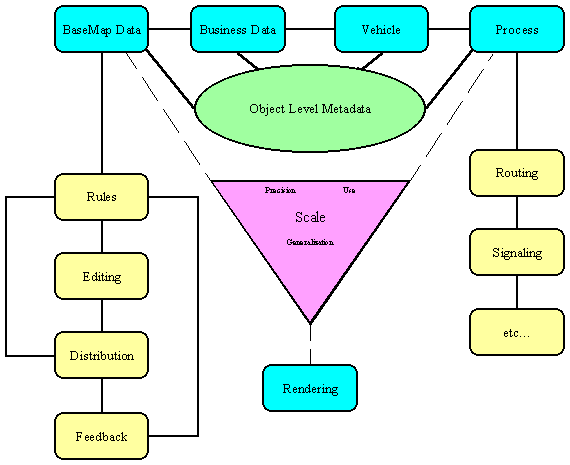
2. Characteristics of a maintainable data model:
-
automated rules
-
merge/split
-
what others?!
-
automated notification (cascade/trigger) this needs to be cached somewhere
(see transaction log)
-
feature/object based
-
collection based
-
transaction log (visualization of transactions, e.g. "db -- go back to
previous state"; transaction date stamp lineage)
-
validation rules
-
at edit level
-
at feature level
-
at dependency level
3. Inverse relationship between table complexity and graphic
complexity
-
if I have very simple road network, need complex turn tables, whereas if
I have a very elaborate road network with ramp objects, etc. then I can
have a very simplistic turn table
but
-
there is a limit to how far we'd want to go with moving towards a simple
turn table
-
users need to be able to adjust to where they'd like to on the slider scale
between table complexity and graphic complexity
Other notes from breakout session:
-
plan for breakout session: lay out scenarios from an application orientation;
focus on scenarios
-
data conversion as a process that feeds the model -- conversion is mechanism
for getting data into the state we need it in for the model
-
LRS should cover conversion between linear reference methods
Brainstorming/Figuring out priorities and issues
*metadata
model
data
*scale
content (aggregate/disaggregate)
precision
generalization
use visualization analysis
cartography scale dependency and/or analysis scale
dependency
analysis on a different scale than you're rendering
*"does an intersection object know how to draw itself at different
scales?"
*"do we need to think about data models that work at different
scales? i.e. data models that are smart enough to handle different
renderings?"
or:
*"do we just worry about whether or not an intersection object
knows how to represent itself?"
*"do we just have a data model that is more simplistic?"
*where does CAD leave off and GIS take over? is this something
we need to be concerned with?
*route calibration tools ------> LRS
*how to address that the way in which things are modeled determines
whether or not something's dynamic
Definitions
Maintenance
model must support or produce tools that promose/allow edits
to features and relationships between features (and this will go to scale)
Example:
-
the Streets Department maintains the Philadelphia centerline file and hands
out revised copies each month to other city departments
-
other city departments have structures that are built on top of and dependent
on this centerline file; they build derivative data sets on top of this
and if the revised centerline file splits a centerline into 2 or 3 separate
segments
-
how does this information get propagated back to the end user, i.e. the
client department?
Issues:
-
what mechanism will simplify this transaction (i.e. propagating changes
up and down the chain)?
-
how to reassociate the links to the street centerline file?
-
what sort of procedures should be set up?
Possible solutions for the centerline file problem?
-
if an arc is split, create a new unique id but retain the old unique in
a new column
-
if can't make a decision, punt and ask the user
-
metadata could include a transaction history
-
instead of having procedures, put together a solution at the object model
level
Question:
Robert Cheetham -- do each of the segments of the model need
a time stamp on them?
What data are we trying to model? i.e., what's on your basemap
1. Capital Improvement
-
work zones
-
conditions
-
accidents
-
traffic volume
-
forecasted traffic volumes
-
road surface
-
thickness
-
shoulder type
-
turning lanes
-
jurisdictional/administrative boundaries
-
patrol district
-
pavement conditions
-
signs, signals, street furniture
2. Roadways
3. business data
eg. 5 tables with 100's of pieces of info about each bridge
*****maintain hooks to the business data****
Change Group Model (for making changes to a base map)
-
db office -- big client of the base map
-
change groups - each office has a steward on the change group who is responsible
for reviewing proposed changes
-
the system will not allow a change to the basemap to happen until each
member of the change group approves and then the db office approves
Problem:
-
we need to have a way to collect multi-resolution data and do agg/disagg
-
we need to be able to draw features at same scale with different
representations
The slider bar example -- table complexity and graphic complexity:
there is an inverse relationsihp between table complexity and
graphic complexity
simple geometry w/ very complex attributes -- e.g. turn tables
for bridges, 1 way streets, divided highways, etc.
complex geometry w/ simple attributes -- e.g. turn tables only
for "no left turn" and other arbitrary road restrictions
which way do we want to go?
Metadata
Object level metadata (transaction log at object level) vs. layer level
metadata (level currently supported by ESRI)