LRMS Test: Cross
Streets Profile (XSP)
The Cross Streets Profile is
one of the messaging protocols in the LRMS. It communicates a location
in terms of an offset distance along a principal street between two cross
streets. For example, the incident below is located at 875 metres
[or
a relative distance: 55% of the way] along Birch St between Main St
and State St. Our task is to test this profile, i.e. to evaluate
its ability to transmit a message meaningfully and unambiguously between
databases.
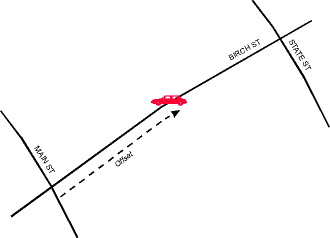 |
|
Figure 1: The
Cross Streets Profile
|
Initial findings (Phase I) were
that the XSP was not a realistic messaging solution in the short term.
We recommended that it be reinforced with location coordinates. This
led to a further series of tests (Phase II). The following is a condensed
report on the results of both Phases I and II.
With the inclusion of coordinates,
the XSP acquires an important characteristic. Since names and coordinates
are entirely independent and could be in conflict, agreement between the
two is a measure of reliability.
Unfortunately, the test results
cannot be encapsulated in a single figure or a short statement. Success
of the XSP depends on a number of factors including
-
inherent effectiveness of the
Profile
-
quality of implementation
flexibility and smarts of algorithms
-
quality of databases
-
vendor/municipal compliance
with standard practices
-
application context and user
requirements some (e.g. emergency management) are more exacting than
others.
Clearly a time-constrained test
effort must steer a course between a rigid, unintelligent interpretation
of the Profile, and a sophisticated implementation driven by substantial
investment and evolution. The test results below reflect current
data sets and vendor practices, which will inevitably improve over time.
The results should be seen as an indication of the types of errors that
can be encountered, as much as a pronouncement on the probability of success.
What's to Test?
Message failure could be caused
by
-
inadequacies in the profile
itself
-
name matching problems
-
database errors
Inadequacies in the Profile
The Profile does not specify
algorithms for composing or decoding the message. Location must be
inferred at the receiving end using only the information provided.
In Figure 2a and 2b below, the XSP message reads "Birch between Cedar and
Cedar," and in Figure 2d, "Birch between Ash and Cedar," both of which
are ambiguous. In Figure 2c the message is "Birch between Birch and
Birch."
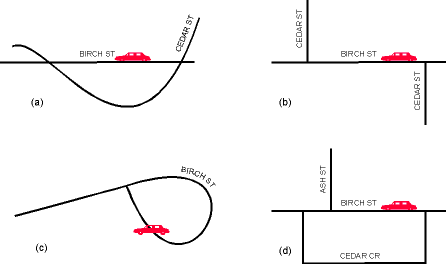 |
|
Figure 2: Some
of the ambiguities not resolvable with the XSP
|
Furthermore, the profile does
not specify the municipality or jurisdiction in which the names occur.
A matching name could be found in another area. Results are therefore
dependent on the geographic extent of the test area. In all these
cases, coordinates are a fall-back or tie-breaker.
Name Matching Problems
Name matching works well
only if databases are accurate. The first problem with the data is
the large proportion of blank name fields. Among the four
databases tested initially, 2045% of all records were blank. Since
the XSP requires three non-blank names, a message could be successfully
composed in only about 33% of all attempts. In 231% of all
cases (varies with database), all three streets in a transfer attempt
were blank.
Note:
-
To an certain extent it is possible
to get around this problem, e.g. as long as the on-street is named, an
algorithm can search outward for the nearest named cross-street in either
direction. However, this relies on the destination database also
having a populated field for those cross-streets.
-
It could be argued that most
of the unnamed streets are remote ranch roads and private tracks, which
are irrelevant to ITS needs. This is true, but there are two counter-arguments:
-
For mission critical applications
such as emergency management services (EMS), remote roads are just as relevant
as major highways.
-
On average, 10% of "major" streets
have blank names (vendors differ in their characterization of "major" streets).
Freeway ramps on which many highway incidents are located are typically
unnamed.
When street names are non-blank,
there are other problems.
-
Alias exists: Ventura Freeway
appears as Hwy 101
-
Spelling/Typographic error:
Venture Freeway
-
Vendor practice
-
conflict in abbreviation or
coding Fwy vs Frwy; US-101 vs Hwy-101
-
prefix/suffix some vendors
distinguish between street name and street type (prefix or suffix).
In the case of Main Street, Main is the proper name, Street
is the street type (suffix). In the case of Via Del Monaco,
Via
Del is a street type (prefix), and Monaco is the proper name.
Some vendors use suffixes but not prefixes, others use bother, or neither.
-
Vendor interpretation: Ward
Memorial Blvd vs Clarence Ward Memorial Blvd.
-
Human error: Birch St coded
as Birch Av
Algorithms can be designed around
these problems. However, the more forgiving the algorithm, the more
likely it is to find the wrong instance of the intended location.
Again, coordinates offer a cross-check.
Database Errors
Database problems may occur
in position, inclusion, topology or attribute.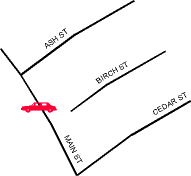
-
Positional errors are documented
elsewhere on the VITAL web page. An absolute or relative offset measured
along Birch St inevitably translates to slightly different positions in
the transmitting and receiving data bases. The extent of discrepancy
depends on the resolution and accuracy of the data bases. The tolerance
to error depends on the application. Examples:
-
airport, hospital, museum (no
specific entrance specified): 1001000 metres
-
hotel, gas station: 2550 metres
-
parking spot, speed restriction
sign: 510 metres
-
Errors of inclusion/exclusion
create topological errors, expanded in the next point.
-
Topological errors are serious
because the XSP is fundamentally topological. In Figure 3, Birch
St comes within a few metres of Main St, but does not intersect it.
Suppose the transmitting database erroneously records an intersection
a common error whereas the receiving database does not. Then a
message that uses this intersection cannot be interpreted at the receiving
end. In the converse situation, where an intersection exists in the
receiving data base but not the transmitting system, intelligent receiver
software can infer the location correctly, although with most link-oriented
data structures in current use, this is difficult.
-
Attribute errors for XSP purposes
refer to incorrect or mis-spelled street names, and misclassification (e.g.
railroad track classified as street).
Test Design
Broadly there are two test components:
-
Name matching to determine probability
of identifying the correct street segment. Since the result of the
transfer is either right or wrong, this can in theory be measured by a
hit rate. In practice this approach is too exacting, and hit rates
are extremely low, in the range of 15%. The Phase II tests are more
forgiving, and use a complex reasoning process to find a likely
hit recall that coordinates are part of the profile tested in Phase II.
-
Measurement of accuracy with
which offsets are transferred, using lab and field tests. Tolerance
to error depends on the user and application, hence there is no right or
wrong result; testing simply documents the degree of accuracy. Offset
measurement and error is the focus of a different LRMS profile the Linear
Referencing Profile which will be tested downstream. Therefore
the tests and results on this component are cursory.
Field tests are conducted using
54 points sampled in and around Santa Barbara. For lab tests, about
10,000 sample points are generated around the county, the sampling density
proportional to the density of roads. The lab tests apply equal weight
to all points, whether freeways or private ranch roads. Field sampled
points are more representative of day-to-day driving routes.
Major roads are tested as
a separate sample. There are wide differences between vendors on
what constitutes a major road (for example, see Vendor
A's version of major streets in Santa Barbara, compared with Vendor
F). Nevertheless, we assume that the receiving database contains
all streets, major and minor, therefore variations in the definition of
"major" affects only the sampling process, not the transfer.
Finally, we test all streets
and major streets in the Santa Barbara-Goleta urban area.
Findings
Test Set A matches sample
points within the originating database. Obviously, using coordinates,
such a test is 100% successful. When coordinates are excluded, only
33% of all sample points have non-blank names required for the transfer.
Of those, about 510% of the transfers are ambiguous (Figure 2).
Test Set B examines
the accuracy with which coordinates alone can identify the correct link
in another database. The transfer is made using coordinates only,
and confirmed by checking cross street names. As documented above,
names are unreliable as a means of judging success. Therefore hits
are scored on a scale of likelihood of matching, with some tolerance of
blank fields. On average, 11% of test points score "likely" matches.
About 66% fall into the possible category, because (a) they match the
wrong street in the right general area, or the wrong segment of the right
street, due to coordinate error, or (b) confidence in name matching is
diluted due to blanks and other name matching problems this is unfortunately
an inherent limitation of the test design. Results are far
better for field-sampled points, which generally lie on named streets.
|
.
|
Mean
|
Min
|
Max
|
|
Likely
|
11%
|
2%
|
18%
|
|
Possible
|
61%
|
52%
|
70%
|
|
Unlikely
|
28%
|
18%
|
45%
|
Table
1: Test Set B
Test Set C transfers
locations using names+coordinates. Obviously, transfers are always
apparently successful. Two questions need to be asked to validate
the transfers:
-
How often does a transfer fall
back to coordinates, because a match is not possible using street names?
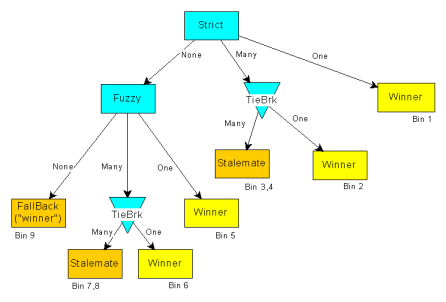
This count is termed Bin 9, a reference to Bin 9 on the
name processing flowchart.
-
How far does the destination
point lie from the source point? The name match could in some cases
point to the wrong street, or if the destination database does not contain
the road referenced in the source, transfer by coordinate may erroneously
snap to the nearest available entity. These problems are addressed
in Test Set D below.
Table 2 summarizes selected
results pertaining to Test Sets C and D. The Bin 9 row indicates
that 35% of all transfers (68% on major streets) fall back to coordinates.
The high fallback for major streets is partly because aliases are not handled
in this test set; they are examined in Test Set E, below.
|
.
|
All Streets
|
Major Streets only
|
|
|
|
|
|
.
|
Mean
|
Min
|
Max
|
Mean
|
Min
|
Max
|
| Bin 9 |
35%
|
16%
|
45%
|
68%
|
38%
|
91%
|
| Snap distance |
|
|
|
|
|
|
| Median distance
(m) |
36.6
|
0.0
|
140.4
|
11.3
|
0.1
|
46.2
|
|
[0, 30m) |
66%
|
37%
|
96%
|
82%
|
52%
|
97%
|
|
[30, 50m) |
4%
|
0%
|
8%
|
9%
|
0%
|
15%
|
| [50m and more) |
30%
|
4%
|
58%
|
23%
|
3%
|
88%
|
Table
2: Test Set C and D
Test Set D is a study
of Euclidean distance between source and destination points, based on the
same transfer tests as Test Set C. We note that distances below 30m
are usually transfers made to the correct destination link, whereas distances
above 50m are generally associated with errors. For single point
transfers, the median distance between source and destination points is
about 35m. Two thirds of all points differ by less than 30m (probably
hitting the correct link), one third by more than 50m (probably hitting
the wrong link). The worst deviation observed in any test is 75 kilometres
clearly a referential error.
Since fallback points are
snapped to the nearest arc without verifying street name, a high "Bin 9"
count in test set C is typically found in conjunction with an artificially
low median distance in D.
Test Set E.
As an afterthought to the original experimental plan, we implement a "fan-out"
algorithm that searches intelligently for any occurrence of the required
street names in the destination database, not necessarily as a triad of
names associated with a single link. In effect, this approach forgives
intervening streets in the destination. The method is particularly
applicable to major-streets-only events typical of ITS.
The algorithm locates the
two intersections {On, From} and {On, To} blank names are not admitted
at all. It examines all possible paths between these two intersections,
constraining the search to links carrying the On-street name (in theory
there should be only one path, but due to database errors and odd municipal
practices, such as forking streets with the same name, multiple paths are
often encountered). It selects the longest such path to be the destination
street.
Fan-out is implemented in
conjunction with other matching processes, in the sequence:
1. Exact match
2. Fan-out using exact match
3. Fuzzy match
4. Fan-out using fuzzy match
The fan-out approach produces
the best results in the entire test series, with a mean fallback rate of
33% (compared with 35% not using the algorithm). For major streets,
the fallback appears to rise from 68% to 72%; however, these numbers are
not comparable because for the fan-out tests, major street events are passed
using only major cross streets; with other tests, major street events may
use minor cross streets. Limiting major streets to the Santa Barbara
urban area, the average fallback is 51%, with a best score of 23%.
Although the magnitude of
improvement due to fan-out is disappointing, it is clear that this method
is the most appropriate implementation of XSP, if only because transfers
should not be confounded by the topology of intervening streets, the presence/absence
of which are often matters of scale and interpretation. Based on
cursory checking of some results, it appears that when fan-out fails, it
is because of database errors, for example:
-
Spelling disagreements in name
records, between databases: Sargosso in database X, Sargoso in database
Y
-
Spelling errors or discontinuities
in naming within a single database, due to which a path cannot be built
connecting the two intersections points.
Some of these errors are easily
fixed. We anticipate that intelligent name matching software could
lower the fallback rate to the region of 1020%.
Conclusions
As we emphasized in the opening
paragraphs, success is a function of numerous factors, from inherent profile
effectiveness to municipal practices, database accuracy and quality
of implementation. Because there is no quality metadata explicitly
associated with the message, there is potential for propagation of error.
Because there are so many dimensions to the tests and results, each potential
user group will need to focus on aspects appropriate to its needs.
For mission-critical applications
such as EMS, the revised XSP (coordinates included) offers a measure of
assurance, in that failure of transfer is clearly indicated by disagreement
of coordinate and name components. Clearly EMS should take no comfort
in the improvements in results due to lenient treatment of blanks in
Phase II tests.
It must be emphasized that
the bulk of the problem with low success rates is not the fault of the
XSP specification, but is a reflection of database quality, particularly
the high incidence of blanks, absence of alias fields in many databases,
and non-standard name parsing and abbreviations. EMS agencies recognize
the need for high quality data; in many areas they are the driving force
behind municipal-level street database quality improvement initiatives.
For best results EMS agencies must ensure that (a) they operate with reference
to a single-source database as far as possible, and (b) they establish
appropriate database quality control and testing measures.
The ITS industry expects
far better success rates from a messaging standard than what has been achieved
in these tests. The following are constructive recommendations for
national-level activities that would lead to better results.
-
Obviously, the ideal long-term
course of action is to re-survey the national street network to uniform
quality standards. Piecemeal efforts are already underway.
Several municipalities have integrated GIS programs in operation, with
varying degrees of coordination between federal, state, county and private
agencies. Outstanding hurdles are (a) the technical difficulty of
finding a common quality standard that suits the needs of all stakeholders
at a reasonable cost, and (b) management challenges to coordinate this
activity at a national scale. Even if re-survey is publicly funded,
commercial vendors will need to make substantial investments in data reorganization
and conflation of nationwide databases. There are two shorter-term
alternatives: standardization of databases, and the ITS Datum.
-
Standardization of databases:
Messaging could be simplified if vendors would populate alias name fields,
and comply with basic standards in street naming, in particular, highway
and ramp nomenclature, field separation and abbreviation. Standardization
of other aspects such as classification and inclusion, are desirable, but
may not be readily achievable in the short term.
-
The ITS Datum is a mid- to long-term
strategy that could potentially
-
alleviate many current messaging
problems,
-
provide an evolutionary framework
for a high-quality national database, and
-
offer a mechanism for continuing
update of highway-related coordinates and attributes, that would survive
future construction and changes in geodetic datums.
Conceptual design of the ITS
Datum is underway; improvement in XSP success may be one of several measures
of its ultimate effectiveness.
Update 1998-05-15
The full text of the LRMS
Cross Streets Profile report is available under Technical
Reports. VITAL acknowledges the support of the Federal
Highways Administration, ITS Joint Program Office, Contract DTFH61-91-Y-30066.
The project was executed under contract to Viggen Corporation. Infrastructure
development that enabled this research was funded by Caltrans.
Research
Home Page

{kind=link}
{kind=link}
{kind=link}